Table of Contents
Introdução
Este é o primeiro de uma série de posts que farei sobre o Spark. Este post é apenas um passo a passo para a instalação do Spark em sua máquina. A princípio, faremos a instalação em uma única máquina, mas posteriormente criaremos um cluster para simular um ambiente de produção com Spark.
Mãos a obra!
Para esta instalação, usaremos o Linux Ubuntu. Para iniciar, você vai precisar de:
-
Oracle Virtual Machine: Vou usar a Oracle Virtual Machine, mas fique à vontade para usar o Hyper-V ou VMware, o que for de sua preferência.
-
Imagem do Linux Ubuntu.
Passo a Passo
No primeiro momento, é necessário criar a máquina virtual. Recomendo a criação de pelo menos 10GB de RAM e 50GB de disco, para você não ter problemas depois de instalar as dependências.
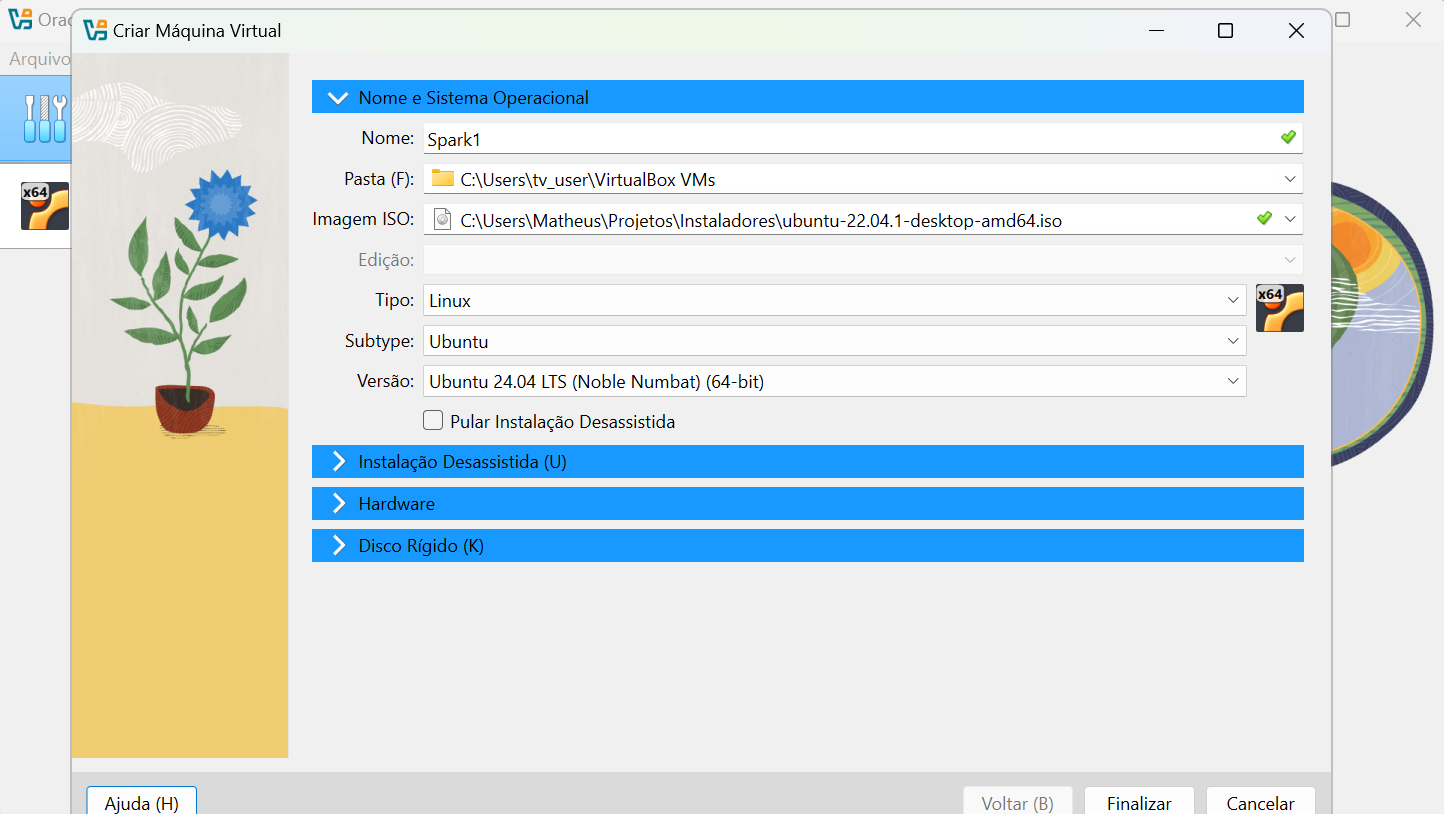
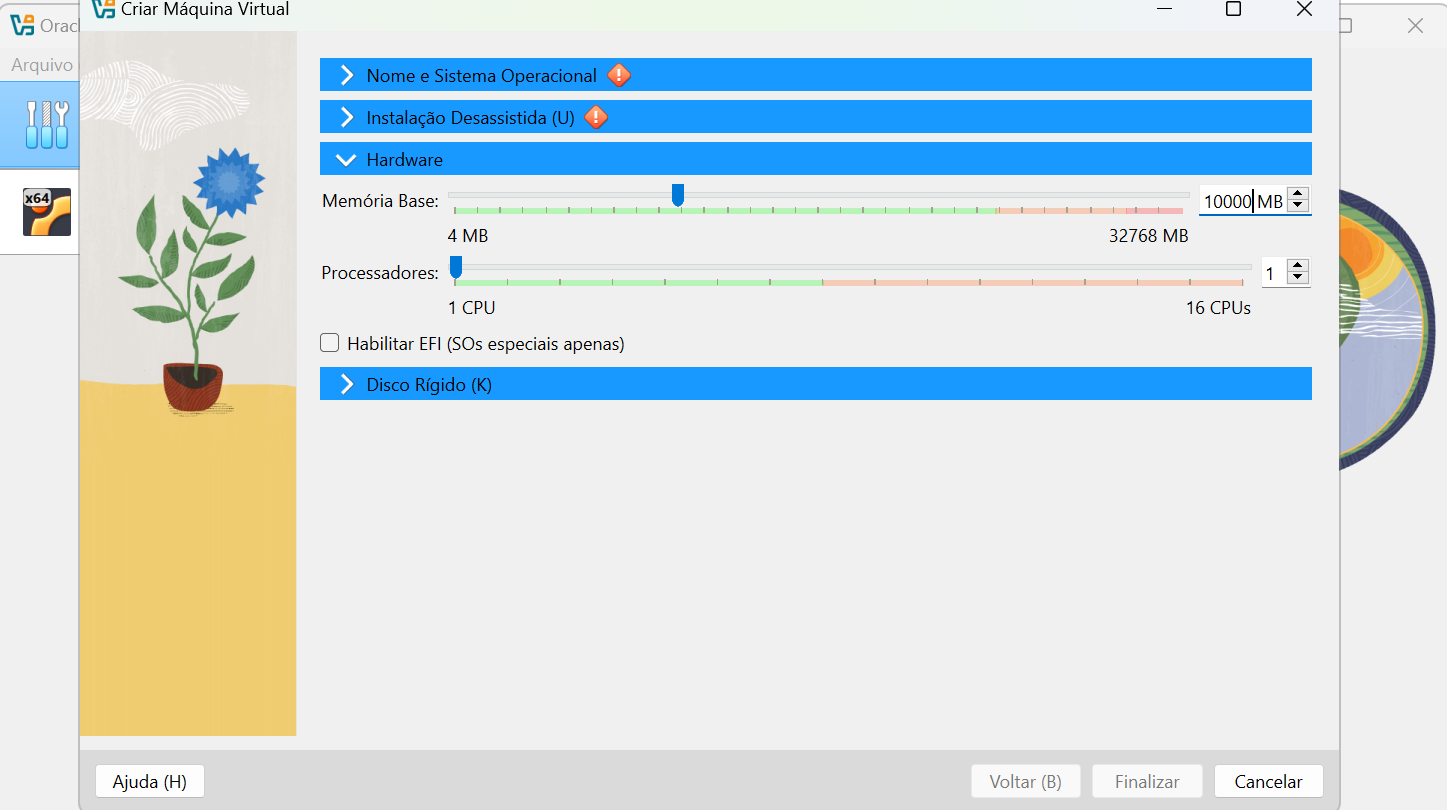
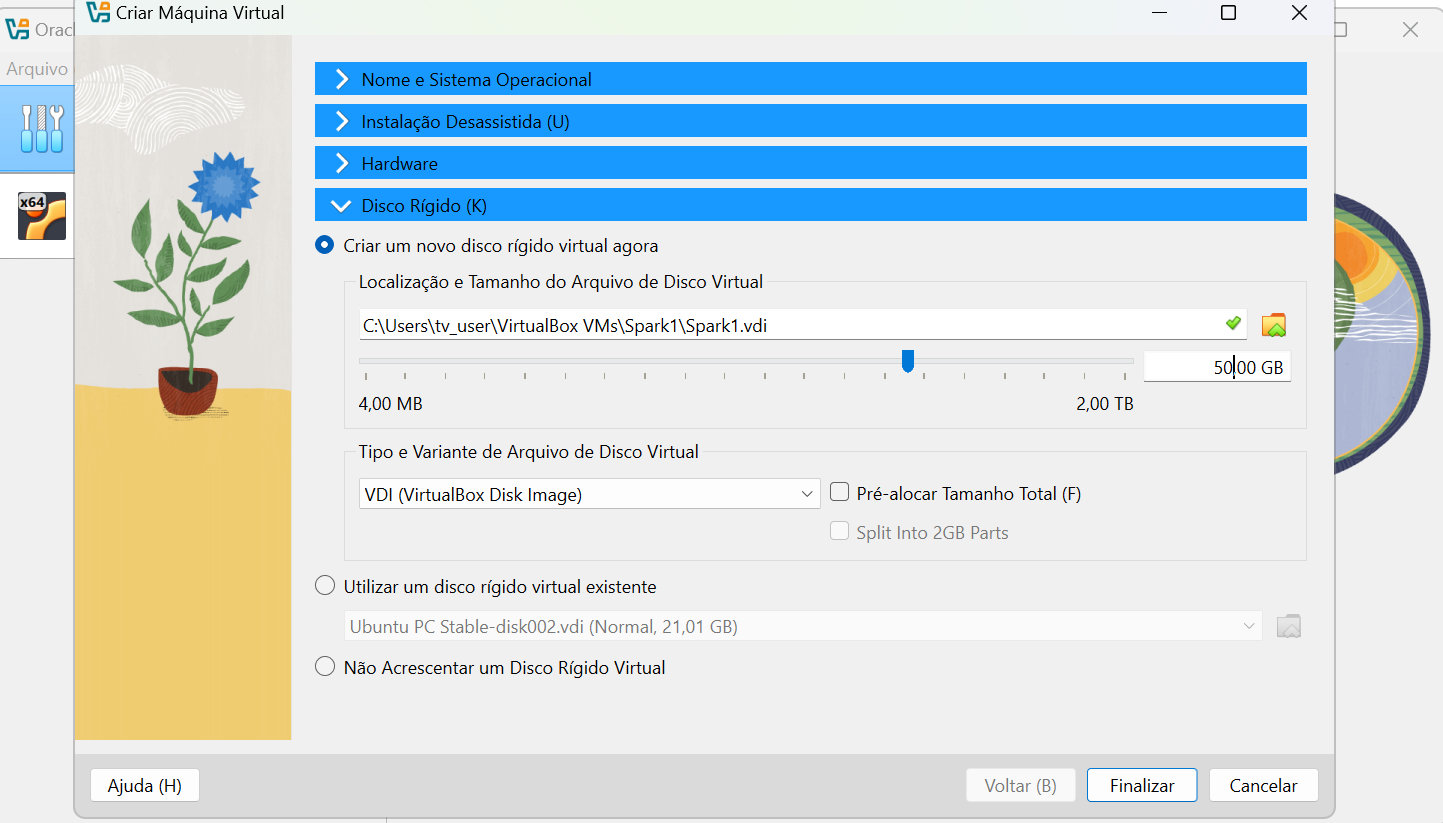
Espere instalar, deve demorar alguns minutos…
Após isso enfrentei alguns problemas hahaha (dois especificamente), problema de usuário sem permissão sudo e dns. Então, eu separei aqui como resolvi exatamente cada um deles:
su -
usermod -a -G sudo vboxuser
Como utilizei o método default da OracleVM -> nela o user é o vboxuser e a senha é changeme, só que ele vem sem permissões. Por isso temos que rodar esse comando. Após isso reinicie a VM e prossiga.
Tive um problema também com o DNS, se você não estiver conseguindo chegar na internet pela url padrão, para resolver esse problema eu realizei os seguintes comandos:
sudo nano /etc/resolv.conf
adicionei nameserver 8.8.8.8 dentro desse arquivo.
Talvez você não sofra esses problemas, mas caso passe por isso também basta seguir o passo a passo acima. Resolvendo esse problemas basta prosseguir:
0. sudo apt update
Para atualizações.
1. sudo apt install curl mlocate default-jdk -y
Instala o JAVA JDK.
2. sudo dpkg --configure -a
Para atualizações.
3. sudo apt -y upgrade
Para atualizações.
4. wget https://dlcdn.apache.org/spark/spark-3.5.3/spark-3.5.3-bin-hadoop3.tgz
Esse comando vai baixar o conteúdo desse link
Esse link foi gerado pelo https://spark.apache.org/downloads.html
5. tar xvf spark-3.5.3-bin-hadoop3.tgz
Esse comando vai abrir em uma pasta o arquivo .tgz
6. sudo mv spark-3.5.3-bin-hadoop3/ /opt/spark
Esse comando vai mover a pasta para a pasta padrão do sprak que é o /opt/spark
7. sudo gedit ~/.bashrc
Esse comando vai abrir o editor de texto padrão do linux nas para as
variáveis de ambiente.
Lá deveremos editar e adicionar a variavel spark_home e path da seguinte forma:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
8. source ~/.bashrc
Esse comando aplica as mudanças feitas nas variáveis de ambiente.
9 start-master.sh
Inicializa o spark no seu computador.
Na etapa etapa 10, coloque a URL que aparece no master. A URL do master deve aparecer na localhost:8080:
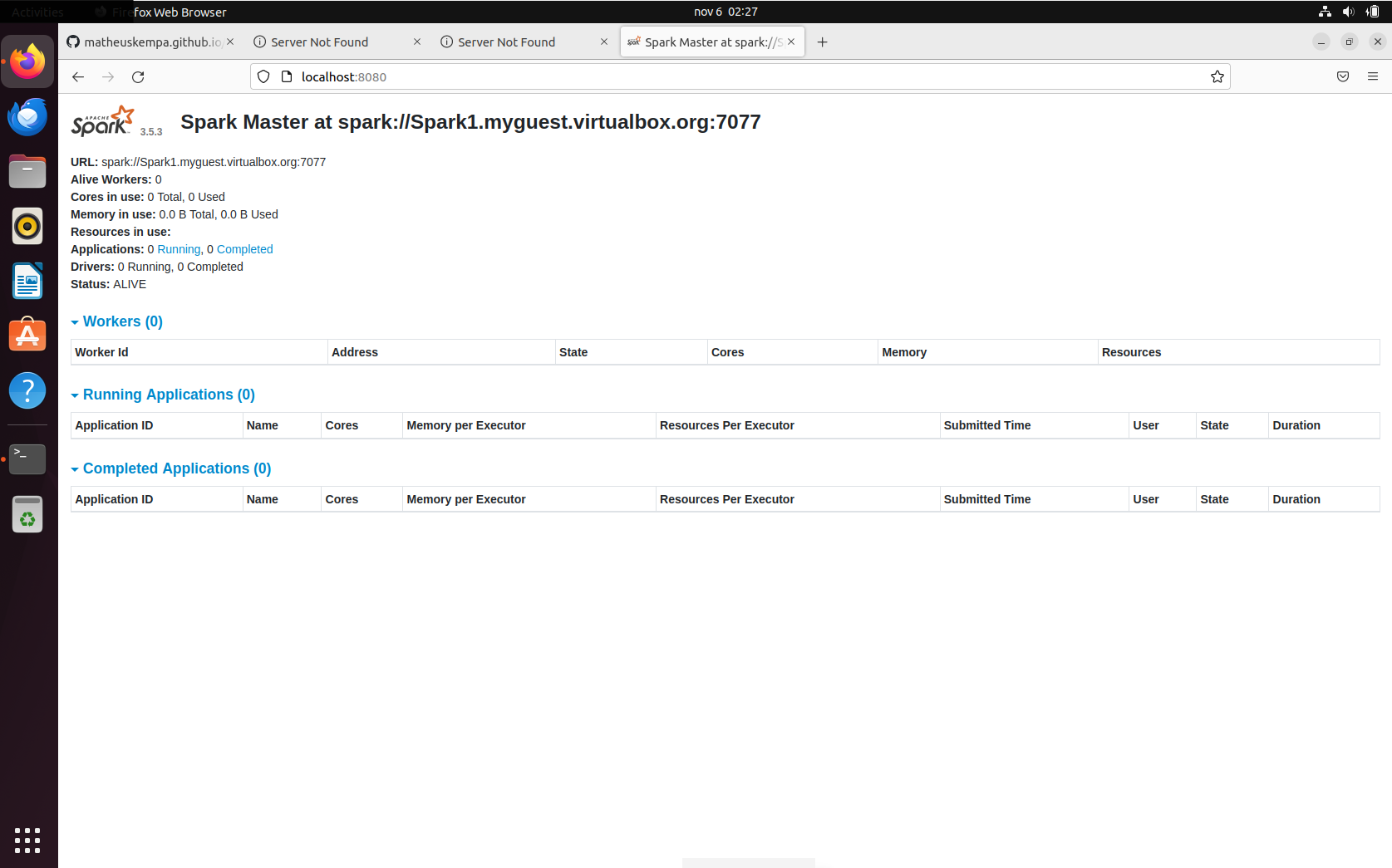
10. /opt/spark/sbin/start-worker.sh {url da master}
11. pyspark
Inicializa o spark em Python.
Ao final ficará da seguinte forma:
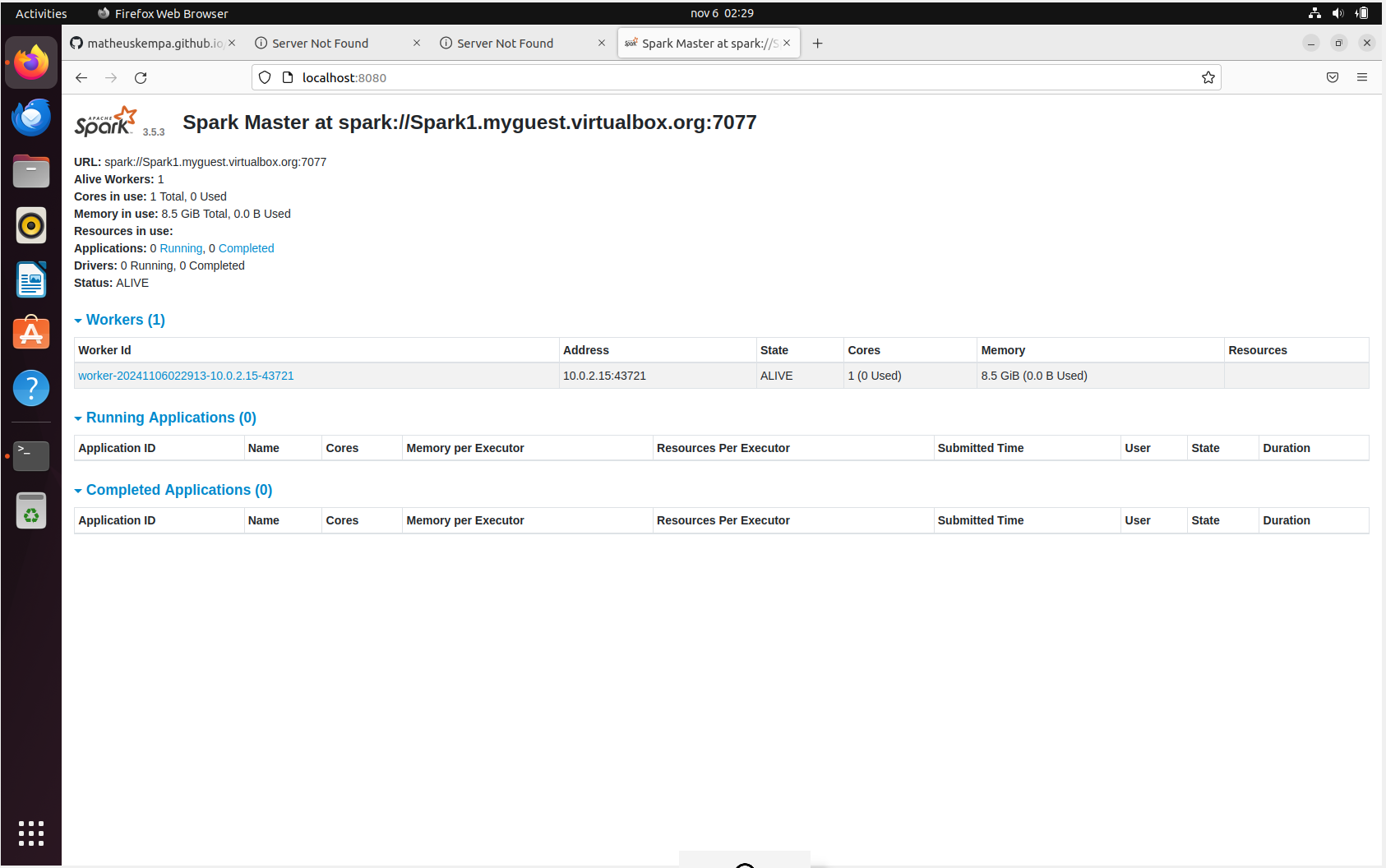
Conclusão
Ao final de todo esse passo a passo, você deve ter o Spark bem instalado em sua máquina e operando 100%!
Sei que este post foi relativamente pequeno, espero que não estejam desapontados. Porém, este é só o primeiro post da série sobre Spark. Será importante, pois vamos replicar para as próximas máquinas que usaremos para o cluster.
Obrigado! E um abraço!
06 Nov 2024 - Matheus Kempa Severino